
개요 및 프로젝트 특징(조건)
작년 이맘때에 샀던 도메인의 만료로 인해 갱신도 했으니 가운영 반년, 실제 운영 1년이 넘어가는 시점이다.
약 22회의 기능 추가/수정 으로 인한 Deploy, 와 30번 이상의 hotfix, 그리고 두번의 대규모 리팩터링을 거친 나름 내가 진행해본 프로젝트 중에서 가장 공을 많이 들이고 여러 기술도 적용시켜보며 지속적으로 신경쓴 프로젝트라고 할수 있을것같다. 특징으로는
1. 최소 비용이 목표라 aws 의 프리티어 ec2를 사용중
2. 특성상 카페 이용 시간대만 사용자가 몰리고, 트래픽이 증가되는 시간대가 정해져있다. 따라서 AutoScale 을 도입.
3. 테스트 상으로 5명의 유저가 분당 150 내외의 GET 요청까지는 무리없이 커버한다.
스프링을 통해 서버를 구축해놓았었고 오토 스케일링 그룹을 만들어 유연하게 대처 할수 있도록 구현을 해놓았었다.
10개월~ 정도는 규모도 작고 이용자도 적어서 잘 이용하고 있었는데 사람이 몰리지 않는 새벽 시간대나 아침 시간대에도 인스턴스 교체(오토 스케일링으로 인한 인스턴스 복제 후에 오래된 인스턴스가 삭제 되는 현상)가 일어나는 문제점이 발생하였다.
또한 서버에서 스케일-아웃 될 시기에 스프링 서버에 트랜잭션이 미완료 상태에 있는 경우 이를 고려하지 않은 인프라 구조와, 서버로 인해서 사용에 불편이 예상되었다.
1. 중요 트랜잭션이 실행되고 있는걸 캐치해서 상태를 보여주는 엔드포인트를 만들어 이를 헬스체크에 사용하고 인프라 구조를 블루/그린 방식으로 변경하거나
2. 최소 인스턴스 개수를 2개로 띄우거나(돈이 2배로!)
여러 방법이 있었는데 ASG 에 보면 왜 스케일-아웃이 일어났는지 모니터링/로깅을 해둔 부분이 있어 확인해보니
Healty check의 기준이 너무 타이트했다!
나는,, ec2 프리티어를 사용하고 있는데 healty check 는 전혀 이를 고려하지 않은 세팅이었던 것이다.
때에 따라서 ec2 인스턴스가 최초 시작후에 apt 업데이트 등을 거치고 spring 코드를 가져오고(CI/CD) 하는 과정에서 적절한 wait()가 이루어지지 않아 cpu 에 부하가 걸렸고, 이로 인해서 ec2 내의 스프링 프로젝트의 시작 시간이 5분 넘게 걸리는 경우도 있었다.
기존 인스턴스 1이 있었고 스케일 업을 통해 새로 만들어진 인스턴스 2가 프로젝트 시작도 채 해보지 않고 healty check 에 걸려서 또다시 중지 처리가 되고 새로운 인스턴스 3가 만들어지는 경우도 존재했다.
따라서
AutoScailing Group 스케일-아웃 조건 러프하게 만들기
를 통해서 스케일-아웃 당시에 인스턴스가 3개,, 4개 발생되는것을 막을수 있었다.
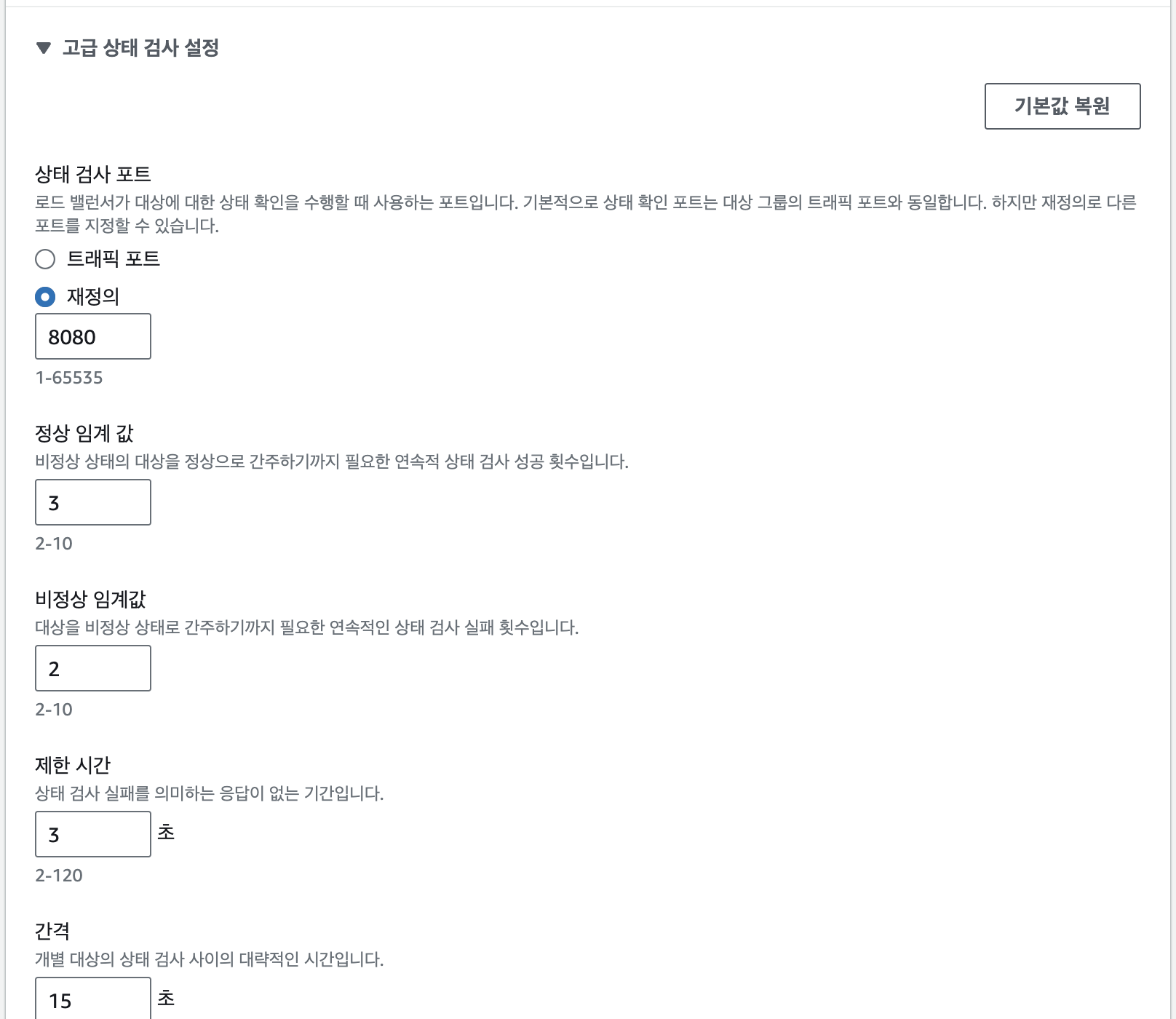
관리 패널 내의 EC2>대상그룹>ALB>대상검사 경로로 들어가면 설정이 가능하다.
그렇게 한달 정도는 별탈 없이 사용했던것 같다.
그리고 당시에 prometheus 를 다른 vpc의 ec2위에 올려서 이 서버를 모니터링 하게 하였고 메모리 또한 준수하게 작동되었었다.
Thread starvation 의 발생

눈으로 바로 보이는 직관적인 문제가 아니라서 살짝(?) 당황했다.. 원인을 찾아야되는 상황
1. EC2의 시스템 로그 확인하기
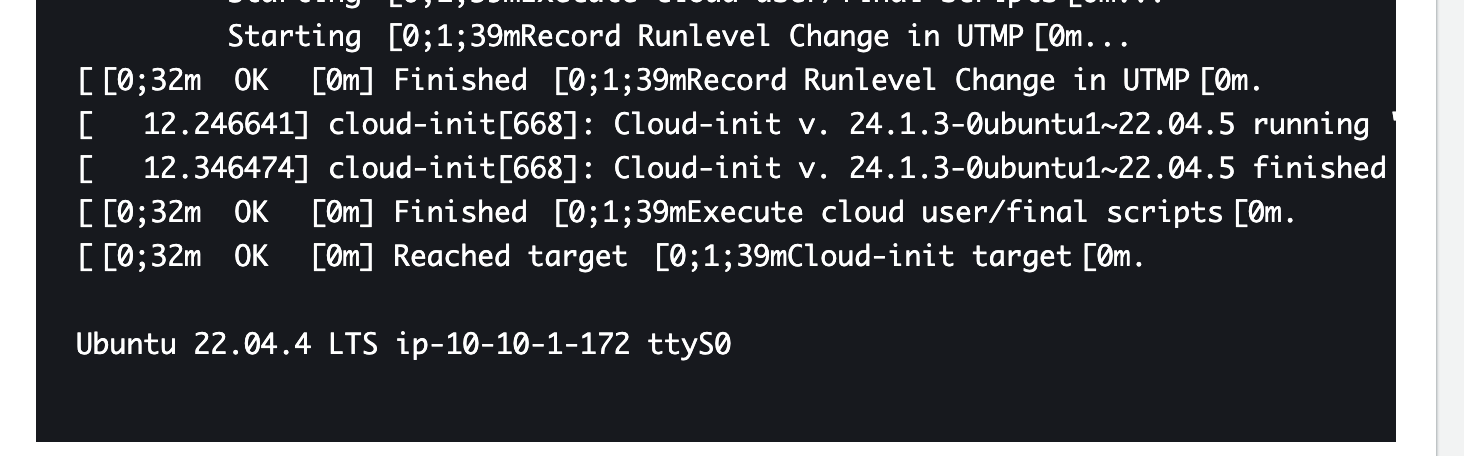
EC2 인스턴스에는 문제가 없이 실행중이었다. 단지 Spring 프로젝트가 셧다운 되서 healty check 가 되지않아 교체되고 있었다.
2. CPU, 메모리 사용량 확인하기
EC2와 로드밸런서의 모니터링 서비스를 활용하여 혹시 트래픽이 증가해서 발생했는지 확인해보았다.
이 역시 평소와 비슷한 정도의 트래픽.
이때 인프라에는 아무 문제가 없다고 판단하고 시선을 제작한 스프링서버로 돌렸다.. ( 시야가 좁아져버린,,)
3. 스프링 프로젝트의 모니터링 확인
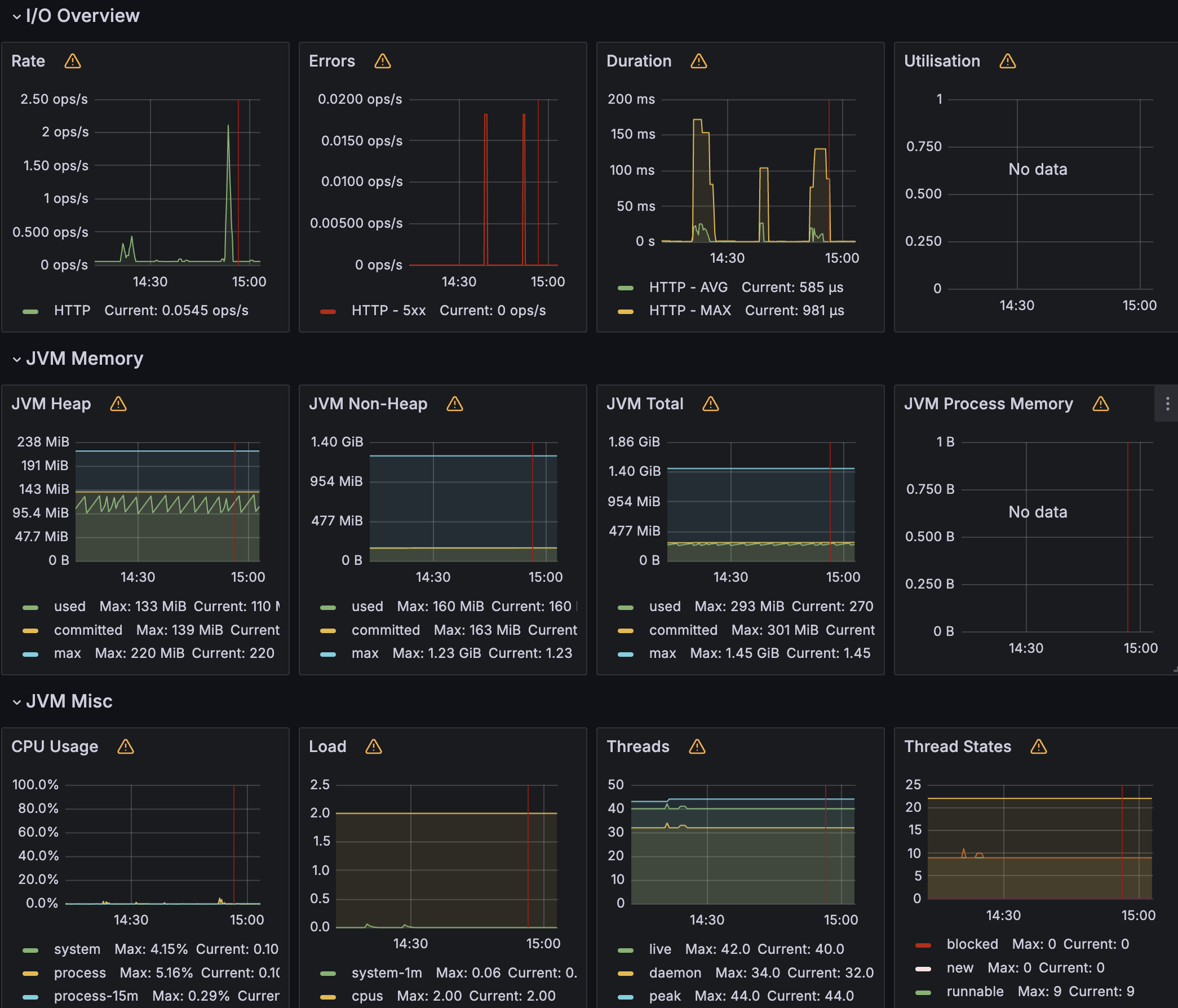
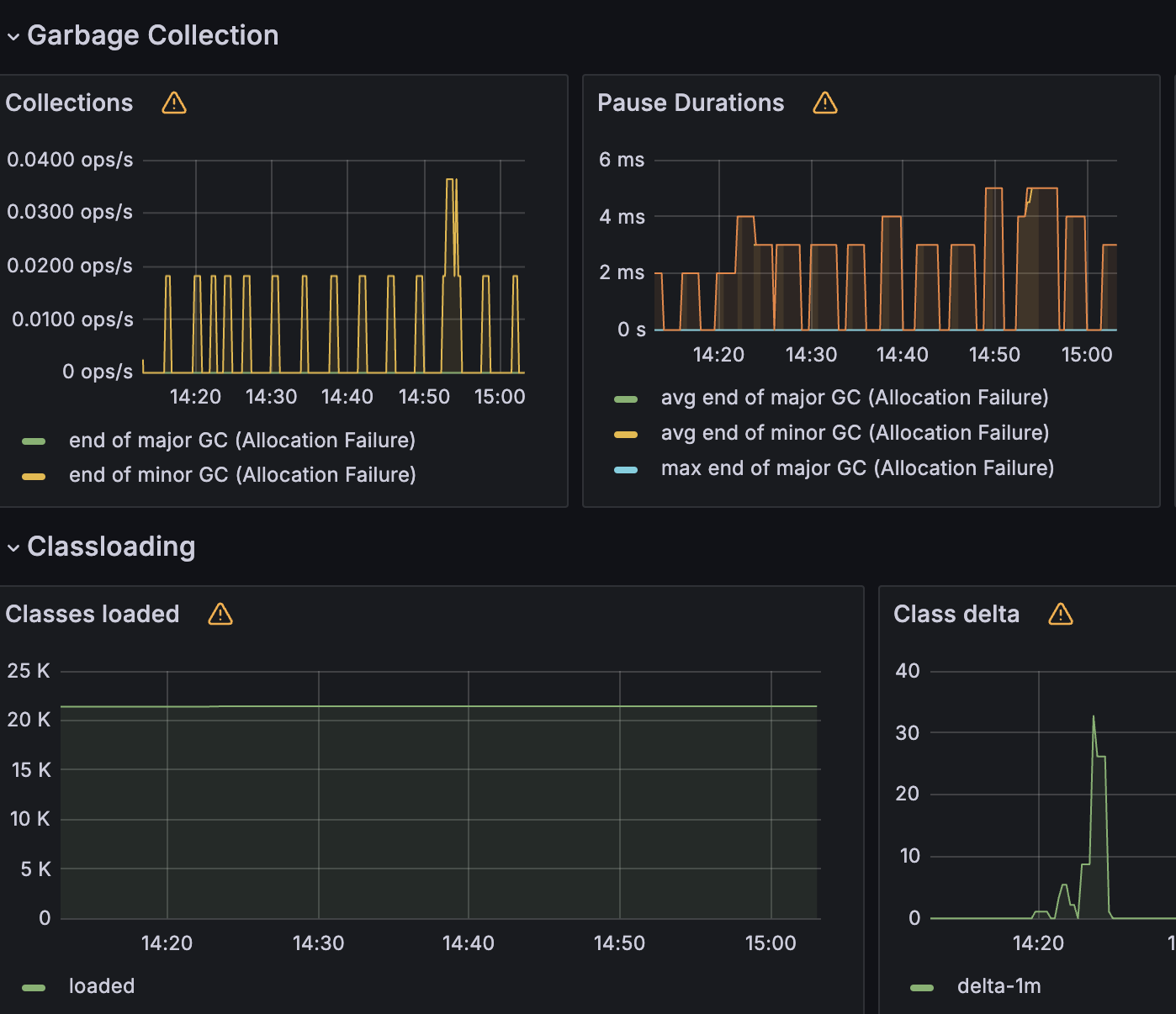
Heap 영역도 안정적으로 이루어지고 GC 또한 균등한 매그니튜드로 실행되고 있음을 확인했다.
그럼 설계 문제로 인해서 메모리 누수가 일어나고 있음이 아닌것이 확인 되었다.
점점 해결의 실마리가 보이지 않고 있었다.
4. 스레드 덤프 분석
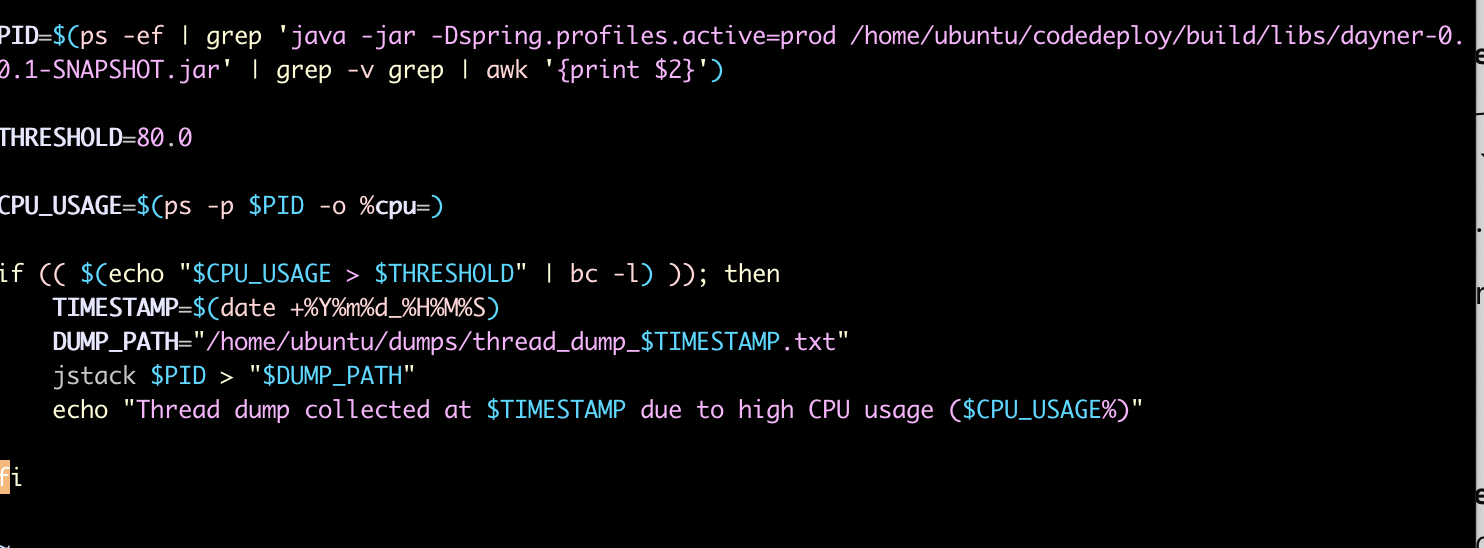

CPU 의 사용량이 70퍼센트를 넘거나 요청이 5건 이상 들어오는 경우를 cloudwatch 로 catch 해서 이벤트 발생 후 10분간 30초 간격으로 자동으로 스레드 덤프를 가져오는 jstack을 활용해 덤프 생성하여 MAT을 통해 확인을 해보았다.
상당한 노가다였지만 발생 당시에 TIMED_WAITING 또는 WAITING 상태에 적은 CPU점유를 가지고 있었고 따로 BLOCKED 상태로 길게 유지 되는 경우가 없었다.
따라서 스레드 덤프에는 문제가 없었고, 여기서 스레드 덤프의 생성이 높은 CPU사용량이나 스레드의 BLOCKED 상태가 장기화 되기 이전에 멈췄다는 것을 발견했다.
따라서 또다시 어플리케이션 외부에 문제가 있다고 판단 하게 되었다.
starvation 을 해결하기 위한 다양한 시도
1. HikariCP 풀사이즈 변경
기본 값으로 10이 설정 되어있었지만 EC2의 프리티어는 코어수 2개에 코어당 스레드수 2개 총 4개의 스레드에 메모리도 8기가 이기에, 시스템 리소스가 과부화 될수 있을것 같다고 판단했다.
그래서 조정을 하려보니 개수 공식이 존재했고, 또한 여러가지 고려할 상황도 존재했다.
Testing MySQL Applications With Java and Testcontainers
Writing comprehensive tests for code that interacts with a database can be a challenge. In this post, we talk about how we can use Testcontainers and JUnit to make it is easier to write tests for Java applications that interct with a MySQL database.
blogs.oracle.com
HikariCP Dead lock에서 벗어나기 (실전편) | 우아한형제들 기술블로그
1부 HikariCP Dead lock에서 벗어나기 (이론편)은 잘 보셨나요? 2부 HikariCP Dead lock에서 벗어나기 (실전편)에서는 실제 장애 사례를 기반으로 장애 원인을 설명하고 해결 사례를 공유하고자 합니다. 그
techblog.woowahan.com
다행히도
id AUTO 전략을 사용한적은 없었고,
1회의 요청에 2개 이상의 커넥션을 만드는 Lazy 로딩으로 설정된 OneToMany나 ManyToMany 전략을 사용하지 않았고,
db 요청에 관한 쿼리는 JPQL 로 fetch join 을 사용하여 1회만에 수행가능하게 만들어놓았다.

하지만 마진을 두어 Cm을 2로 잡았고 Tn 은 현재 Ec2 의 스펙을 따라서
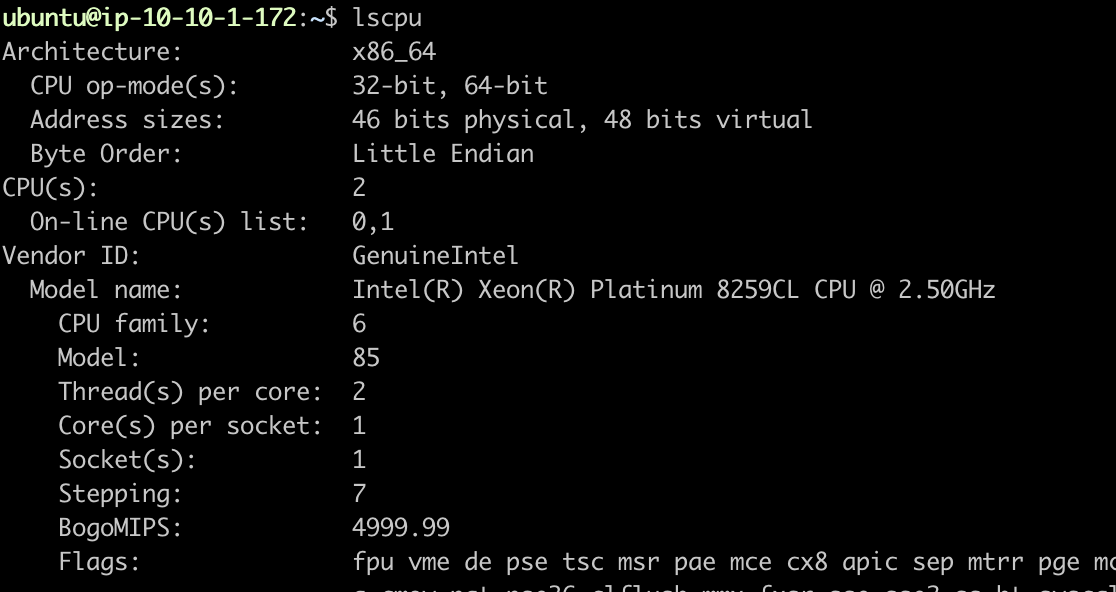
4로 설정하여 최소 풀의 크기는 5, 여기에 1의 추가 마진을 주어 6으로 변경 해보기도 하였다.
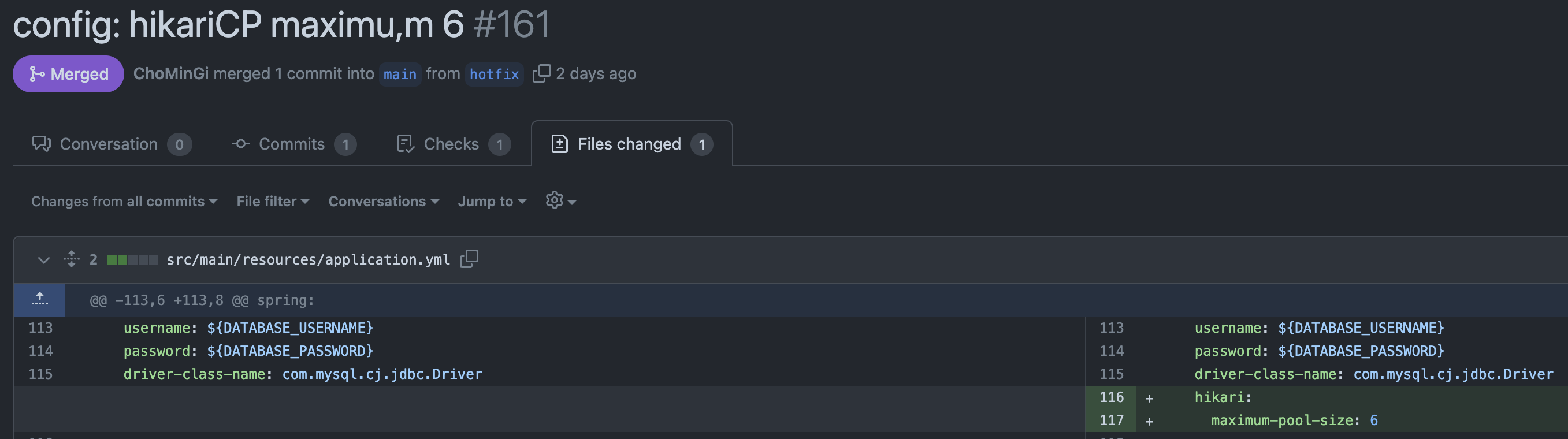
결과는 아쉽게도 셧다운 문제가 해결되지 않았다.
2. EC2 의 스왑 메모리 적용
현재 사용하고 있는 ec2 의 메모리는 총 1GB로 Spring 에서 사용할수 있는 메모리의 수가 부족한것 같다는 판단이 들었다.
그럼 메모리가 높은 ec2 인스턴스로 교체를 해보자
-> 최소한의 유지비용을 위해서 프리티어를 쓰기 때문에 더 높은 인스턴스로의 교체는 최후의 수단이다.
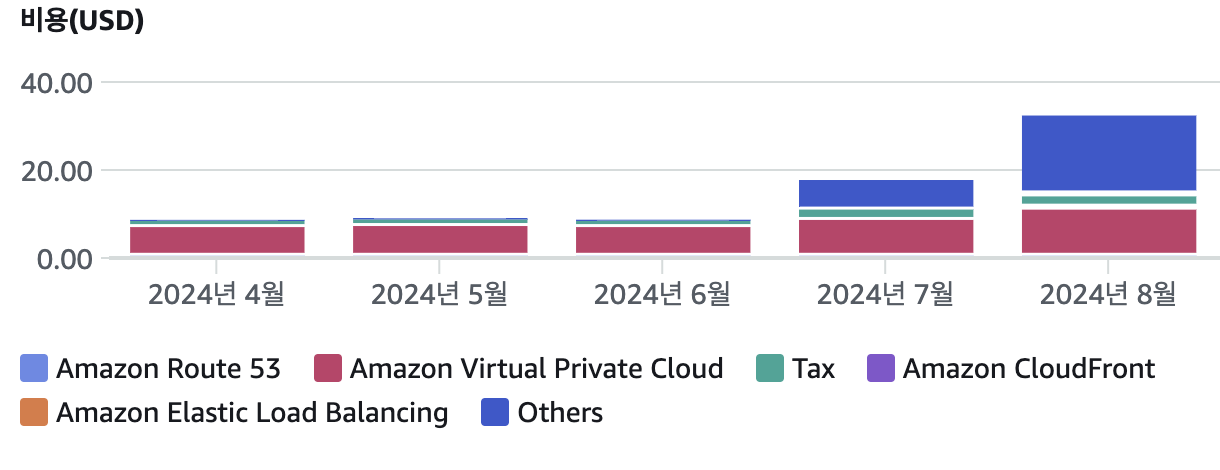
클라이언트로 하여금 가끔 끊기는 현상을 방지하기 위해 운영비를 2배로 늘렸습니다. 는 정말 최후의 수단인거다.
다행히도, EC2는 PC의 가상 메모리처럼 디스크용량을 메모리로 스왑하여 사용이 가능하다.
스왑 파일을 사용하여 Amazon EC2 인스턴스에서 메모리를 스왑 스페이스로 할당합니다.
Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에서 스왑 파일로 사용할 메모리를 할당하고 싶습니다. 어떻게 해야 하나요?
repost.aws

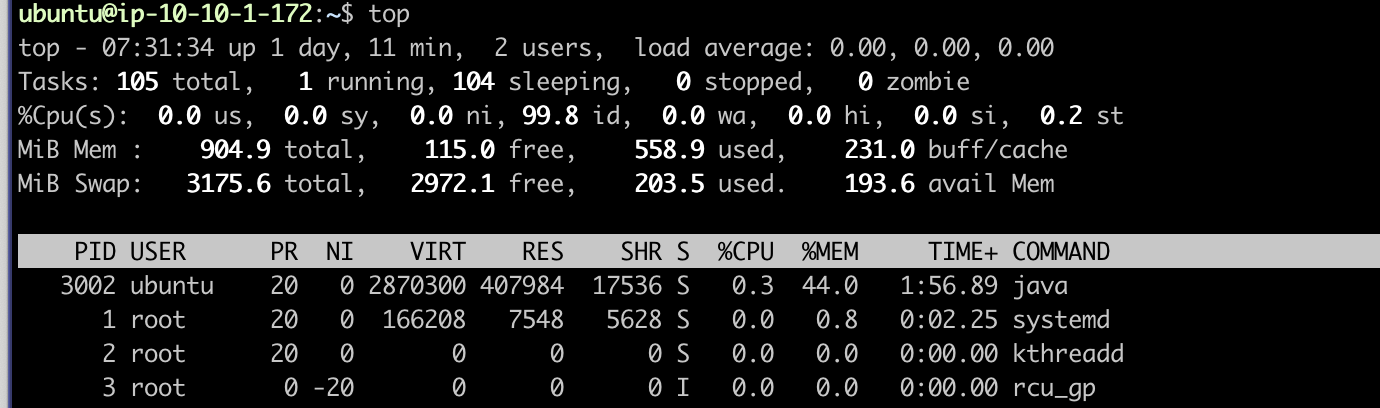
그렇다면 해결이 되었을까?
결론부터 말하자면 스왑 메모리의 도입으로 Stravation으로 인한 셧다운 문제는 해결되었다.
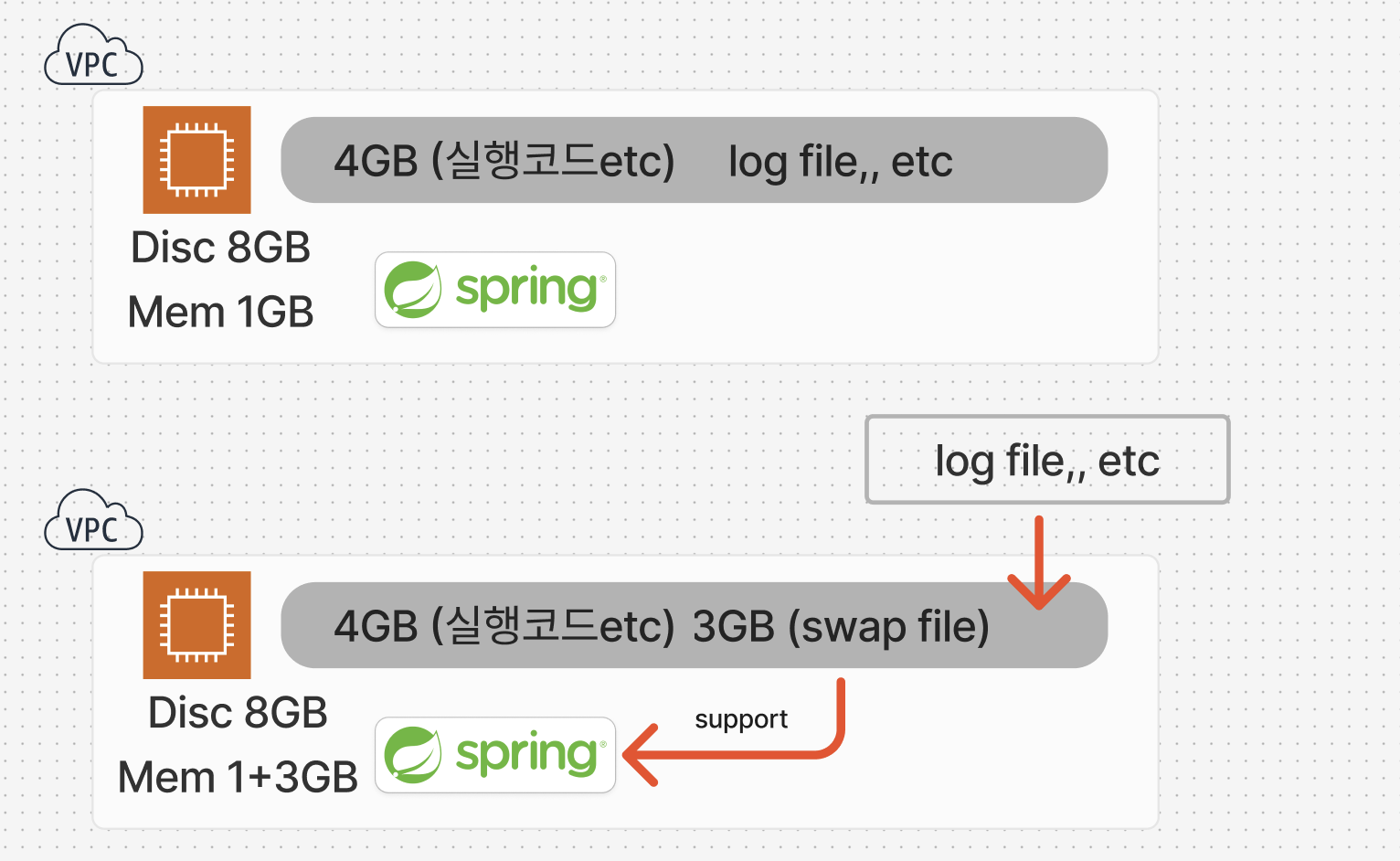
OOM 의 발생
하지만 얼마 지나지 않아 OOM(Out Of Memory)가 발생하게 되었는데..
스왑 메모리 할당으로 인한 디스크 공간 부족
OOM, 즉 메모리가 부족하다는거다.
어? 분명 스왑메모리로 메모리 용량도 높였고.. 모니터링 내역을 봐도 특이점은 보이지 않았다.
디스크 공간은 충분할까? 싶어서 인스턴스 status 를 확인해보았더니

유후 디스크 공간을 스왑메모리로 할당을 해버리면서 거의 모든 디스크 공간을 사용하고 말았던 것이었다.
왜 사전에 확인을 못했을까?
사용하고 있는 프리티어의 EC2 인스턴스 기본 설정 디스크 공간 크기는 8기가인데, 초창기에 단순히 java 파일과 jdk 설치+aws 클라이언트 설치만을 했을때 많아도 4기가가 넘지 않아 30기가까지의 디스크 공간 추가가 가능하지만 설정을 따로 변경하지는 않았었다.

여분의 4기가는 추후 CI/CD 를 구축하면서 1. code Deploy관련된 파일과 설치가 이루어지고, 2. 운영하면서 발생하는 여러 로그 파일들과 3. 스왑메모리로 3기가를 할당했기에 디스크 공간이 부족해진것이었다.
추가 디스크 공간 할당
바로 EC2 내리고 볼륨 관리자 EBS에서 시원하게 12기가를 추가해서 20기가를 맞춰주었다.
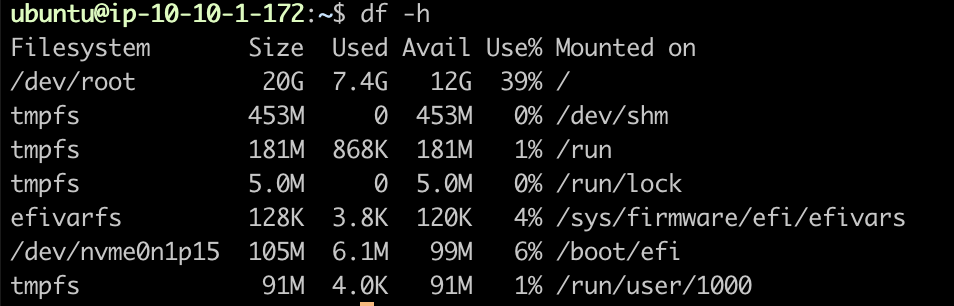

(0902추가)
현재 거의 한달 정도가 지났는데 해당 Starving 문제는 해결되었다.
오래 운영해오기도 했고 최근 돈을 들여서 새로운 디자이너분을 통해 새 디자인도 나온 만큼 내가 맡고있는 서버의 안정적인 운영이 뒷받침 되어줘야 한다고 생각하던 찰나에 여러번의 서버 이슈가 발생했고 매번 다른 오류를 뱉어내서 마음고생도 했지만
해결 과정을 통해서 JVM 의 구조나 여러 OOM을 직접 경험해보기도 하고 스레드 덤프를 확인해보기도 하면서 경험치가 쌓인것 같다.
'Dayner 프로젝트' 카테고리의 다른 글
| Dayner에서 이벤트성, 일회성 쿠폰을 발급하고 관리하는 방법 [1] (0) | 2025.03.07 |
|---|---|
| Dayner에서 구매 이력을 관리하는 방법 [1] (feat: 개인정보보호법, 원장 데이터) (4) | 2024.08.31 |
| 영업시간 디자인 변경에 대응한 리팩토링 일지 [2] (feat: 버전별 API 캐시 전략) (0) | 2024.08.25 |
| 영업시간 디자인 변경에 대응한 리팩토링 일지 [1] (feat: 연결된 일정 구현하기) (0) | 2024.08.22 |
| Dayner 2차 리팩토링 계획(feat: 멀티 모듈화) (0) | 2024.04.03 |
개요 및 프로젝트 특징(조건)
작년 이맘때에 샀던 도메인의 만료로 인해 갱신도 했으니 가운영 반년, 실제 운영 1년이 넘어가는 시점이다.
약 22회의 기능 추가/수정 으로 인한 Deploy, 와 30번 이상의 hotfix, 그리고 두번의 대규모 리팩터링을 거친 나름 내가 진행해본 프로젝트 중에서 가장 공을 많이 들이고 여러 기술도 적용시켜보며 지속적으로 신경쓴 프로젝트라고 할수 있을것같다. 특징으로는
1. 최소 비용이 목표라 aws 의 프리티어 ec2를 사용중
2. 특성상 카페 이용 시간대만 사용자가 몰리고, 트래픽이 증가되는 시간대가 정해져있다. 따라서 AutoScale 을 도입.
3. 테스트 상으로 5명의 유저가 분당 150 내외의 GET 요청까지는 무리없이 커버한다.
스프링을 통해 서버를 구축해놓았었고 오토 스케일링 그룹을 만들어 유연하게 대처 할수 있도록 구현을 해놓았었다.
10개월~ 정도는 규모도 작고 이용자도 적어서 잘 이용하고 있었는데 사람이 몰리지 않는 새벽 시간대나 아침 시간대에도 인스턴스 교체(오토 스케일링으로 인한 인스턴스 복제 후에 오래된 인스턴스가 삭제 되는 현상)가 일어나는 문제점이 발생하였다.
또한 서버에서 스케일-아웃 될 시기에 스프링 서버에 트랜잭션이 미완료 상태에 있는 경우 이를 고려하지 않은 인프라 구조와, 서버로 인해서 사용에 불편이 예상되었다.
1. 중요 트랜잭션이 실행되고 있는걸 캐치해서 상태를 보여주는 엔드포인트를 만들어 이를 헬스체크에 사용하고 인프라 구조를 블루/그린 방식으로 변경하거나
2. 최소 인스턴스 개수를 2개로 띄우거나(돈이 2배로!)
여러 방법이 있었는데 ASG 에 보면 왜 스케일-아웃이 일어났는지 모니터링/로깅을 해둔 부분이 있어 확인해보니
Healty check의 기준이 너무 타이트했다!
나는,, ec2 프리티어를 사용하고 있는데 healty check 는 전혀 이를 고려하지 않은 세팅이었던 것이다.
때에 따라서 ec2 인스턴스가 최초 시작후에 apt 업데이트 등을 거치고 spring 코드를 가져오고(CI/CD) 하는 과정에서 적절한 wait()가 이루어지지 않아 cpu 에 부하가 걸렸고, 이로 인해서 ec2 내의 스프링 프로젝트의 시작 시간이 5분 넘게 걸리는 경우도 있었다.
기존 인스턴스 1이 있었고 스케일 업을 통해 새로 만들어진 인스턴스 2가 프로젝트 시작도 채 해보지 않고 healty check 에 걸려서 또다시 중지 처리가 되고 새로운 인스턴스 3가 만들어지는 경우도 존재했다.
따라서
AutoScailing Group 스케일-아웃 조건 러프하게 만들기
를 통해서 스케일-아웃 당시에 인스턴스가 3개,, 4개 발생되는것을 막을수 있었다.
관리 패널 내의 EC2>대상그룹>ALB>대상검사 경로로 들어가면 설정이 가능하다.
그렇게 한달 정도는 별탈 없이 사용했던것 같다.
그리고 당시에 prometheus 를 다른 vpc의 ec2위에 올려서 이 서버를 모니터링 하게 하였고 메모리 또한 준수하게 작동되었었다.
Thread starvation 의 발생
눈으로 바로 보이는 직관적인 문제가 아니라서 살짝(?) 당황했다.. 원인을 찾아야되는 상황
1. EC2의 시스템 로그 확인하기
EC2 인스턴스에는 문제가 없이 실행중이었다. 단지 Spring 프로젝트가 셧다운 되서 healty check 가 되지않아 교체되고 있었다.
2. CPU, 메모리 사용량 확인하기
EC2와 로드밸런서의 모니터링 서비스를 활용하여 혹시 트래픽이 증가해서 발생했는지 확인해보았다.
이 역시 평소와 비슷한 정도의 트래픽.
이때 인프라에는 아무 문제가 없다고 판단하고 시선을 제작한 스프링서버로 돌렸다.. ( 시야가 좁아져버린,,)
3. 스프링 프로젝트의 모니터링 확인
Heap 영역도 안정적으로 이루어지고 GC 또한 균등한 매그니튜드로 실행되고 있음을 확인했다.
그럼 설계 문제로 인해서 메모리 누수가 일어나고 있음이 아닌것이 확인 되었다.
점점 해결의 실마리가 보이지 않고 있었다.
4. 스레드 덤프 분석
CPU 의 사용량이 70퍼센트를 넘거나 요청이 5건 이상 들어오는 경우를 cloudwatch 로 catch 해서 이벤트 발생 후 10분간 30초 간격으로 자동으로 스레드 덤프를 가져오는 jstack을 활용해 덤프 생성하여 MAT을 통해 확인을 해보았다.
상당한 노가다였지만 발생 당시에 TIMED_WAITING 또는 WAITING 상태에 적은 CPU점유를 가지고 있었고 따로 BLOCKED 상태로 길게 유지 되는 경우가 없었다.
따라서 스레드 덤프에는 문제가 없었고, 여기서 스레드 덤프의 생성이 높은 CPU사용량이나 스레드의 BLOCKED 상태가 장기화 되기 이전에 멈췄다는 것을 발견했다.
따라서 또다시 어플리케이션 외부에 문제가 있다고 판단 하게 되었다.
starvation 을 해결하기 위한 다양한 시도
1. HikariCP 풀사이즈 변경
기본 값으로 10이 설정 되어있었지만 EC2의 프리티어는 코어수 2개에 코어당 스레드수 2개 총 4개의 스레드에 메모리도 8기가 이기에, 시스템 리소스가 과부화 될수 있을것 같다고 판단했다.
그래서 조정을 하려보니 개수 공식이 존재했고, 또한 여러가지 고려할 상황도 존재했다.
Testing MySQL Applications With Java and Testcontainers
Writing comprehensive tests for code that interacts with a database can be a challenge. In this post, we talk about how we can use Testcontainers and JUnit to make it is easier to write tests for Java applications that interct with a MySQL database.
blogs.oracle.com
HikariCP Dead lock에서 벗어나기 (실전편) | 우아한형제들 기술블로그
1부 HikariCP Dead lock에서 벗어나기 (이론편)은 잘 보셨나요? 2부 HikariCP Dead lock에서 벗어나기 (실전편)에서는 실제 장애 사례를 기반으로 장애 원인을 설명하고 해결 사례를 공유하고자 합니다. 그
techblog.woowahan.com
다행히도
id AUTO 전략을 사용한적은 없었고,
1회의 요청에 2개 이상의 커넥션을 만드는 Lazy 로딩으로 설정된 OneToMany나 ManyToMany 전략을 사용하지 않았고,
db 요청에 관한 쿼리는 JPQL 로 fetch join 을 사용하여 1회만에 수행가능하게 만들어놓았다.
하지만 마진을 두어 Cm을 2로 잡았고 Tn 은 현재 Ec2 의 스펙을 따라서
4로 설정하여 최소 풀의 크기는 5, 여기에 1의 추가 마진을 주어 6으로 변경 해보기도 하였다.
결과는 아쉽게도 셧다운 문제가 해결되지 않았다.
2. EC2 의 스왑 메모리 적용
현재 사용하고 있는 ec2 의 메모리는 총 1GB로 Spring 에서 사용할수 있는 메모리의 수가 부족한것 같다는 판단이 들었다.
그럼 메모리가 높은 ec2 인스턴스로 교체를 해보자
-> 최소한의 유지비용을 위해서 프리티어를 쓰기 때문에 더 높은 인스턴스로의 교체는 최후의 수단이다.
클라이언트로 하여금 가끔 끊기는 현상을 방지하기 위해 운영비를 2배로 늘렸습니다. 는 정말 최후의 수단인거다.
다행히도, EC2는 PC의 가상 메모리처럼 디스크용량을 메모리로 스왑하여 사용이 가능하다.
스왑 파일을 사용하여 Amazon EC2 인스턴스에서 메모리를 스왑 스페이스로 할당합니다.
Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에서 스왑 파일로 사용할 메모리를 할당하고 싶습니다. 어떻게 해야 하나요?
repost.aws
그렇다면 해결이 되었을까?
결론부터 말하자면 스왑 메모리의 도입으로 Stravation으로 인한 셧다운 문제는 해결되었다.
OOM 의 발생
하지만 얼마 지나지 않아 OOM(Out Of Memory)가 발생하게 되었는데..
스왑 메모리 할당으로 인한 디스크 공간 부족
OOM, 즉 메모리가 부족하다는거다.
어? 분명 스왑메모리로 메모리 용량도 높였고.. 모니터링 내역을 봐도 특이점은 보이지 않았다.
디스크 공간은 충분할까? 싶어서 인스턴스 status 를 확인해보았더니
유후 디스크 공간을 스왑메모리로 할당을 해버리면서 거의 모든 디스크 공간을 사용하고 말았던 것이었다.
왜 사전에 확인을 못했을까?
사용하고 있는 프리티어의 EC2 인스턴스 기본 설정 디스크 공간 크기는 8기가인데, 초창기에 단순히 java 파일과 jdk 설치+aws 클라이언트 설치만을 했을때 많아도 4기가가 넘지 않아 30기가까지의 디스크 공간 추가가 가능하지만 설정을 따로 변경하지는 않았었다.
여분의 4기가는 추후 CI/CD 를 구축하면서 1. code Deploy관련된 파일과 설치가 이루어지고, 2. 운영하면서 발생하는 여러 로그 파일들과 3. 스왑메모리로 3기가를 할당했기에 디스크 공간이 부족해진것이었다.
추가 디스크 공간 할당
바로 EC2 내리고 볼륨 관리자 EBS에서 시원하게 12기가를 추가해서 20기가를 맞춰주었다.
(0902추가)
현재 거의 한달 정도가 지났는데 해당 Starving 문제는 해결되었다.
오래 운영해오기도 했고 최근 돈을 들여서 새로운 디자이너분을 통해 새 디자인도 나온 만큼 내가 맡고있는 서버의 안정적인 운영이 뒷받침 되어줘야 한다고 생각하던 찰나에 여러번의 서버 이슈가 발생했고 매번 다른 오류를 뱉어내서 마음고생도 했지만
해결 과정을 통해서 JVM 의 구조나 여러 OOM을 직접 경험해보기도 하고 스레드 덤프를 확인해보기도 하면서 경험치가 쌓인것 같다.
'Dayner 프로젝트' 카테고리의 다른 글
| Dayner에서 이벤트성, 일회성 쿠폰을 발급하고 관리하는 방법 [1] (0) | 2025.03.07 |
|---|---|
| Dayner에서 구매 이력을 관리하는 방법 [1] (feat: 개인정보보호법, 원장 데이터) (4) | 2024.08.31 |
| 영업시간 디자인 변경에 대응한 리팩토링 일지 [2] (feat: 버전별 API 캐시 전략) (0) | 2024.08.25 |
| 영업시간 디자인 변경에 대응한 리팩토링 일지 [1] (feat: 연결된 일정 구현하기) (0) | 2024.08.22 |
| Dayner 2차 리팩토링 계획(feat: 멀티 모듈화) (0) | 2024.04.03 |