
목차
계기 및 목적
최근 알고리즘 공부를 하기 시작하면서 블로그 포스팅도 함께 시작하였는데 문제에 대한 내 코드 리뷰를 적는데에도 오랜 시간이 걸리는데 각 문제의 제목이나 번호등을 따로 작성하는 것이 번거로워 생각하게 되었다.
추가적으로 숏코딩의 코드 길이(Byte)나 평균 정답자의 코드 길이도 출력하여 나의 코드 길이는 어느정도의 위치에 있는지에 대한 위젯도 만들어보려고 한다.
깃허브 (업데이트중) ⬇⬇⬇
GitHub - ChoMinGi/Baekjoon-crawling: To reduce the hassle of blog posting
To reduce the hassle of blog posting. Contribute to ChoMinGi/Baekjoon-crawling development by creating an account on GitHub.
github.com
Beautiful Soup 사용하여 html 가져오기
BeautifulSoup는 일종의 라이브러리로 웹사이트 상의 구문을 분석하는 모듈이다.
csv 등으로 변환하기 쉬운 html 형식으로 BeautifulSoup 의 객체를 형성하여 사용한다.
import requests
from bs4 import BeautifulSoup
url = '가져올 웹사이트 주소'
response=requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
else :
print(response.status_code)
여기서 response 변수에 해당 웹사이트의 requests 통해 받아온 상태 코드가 200인 경우에 실행이 되도록 되어있는데 이는 HTTP 상태코드가 200인 경우에는 서버가 요청을 제대로 처리했다 는 뜻으로 주로 서버가 요청한 페이지를 제공했다는 의미로 쓰인다.
따라서 올바르게 받아오지 못하는 경우 그 이유를 알기 위해서 else 문에 상태코드를 출력하는 함수를 추가하였고 출력값에 따라서 코드의 문제인지 웹사이트상의 문제인지를 판별할 수 있게된다.
상태코드에 대해서 자세히 알기 위해서는 ⬇⬇⬇
Hypertext Transfer Protocol (HTTP) Status Code Registry
www.iana.org
받아온 html 에서 필요한 위치 찾기
크롬으로 해당 페이지에 접속한다 > F12 로 콘솔창을 띄운다 > 요소 탭에서 찾아본다.
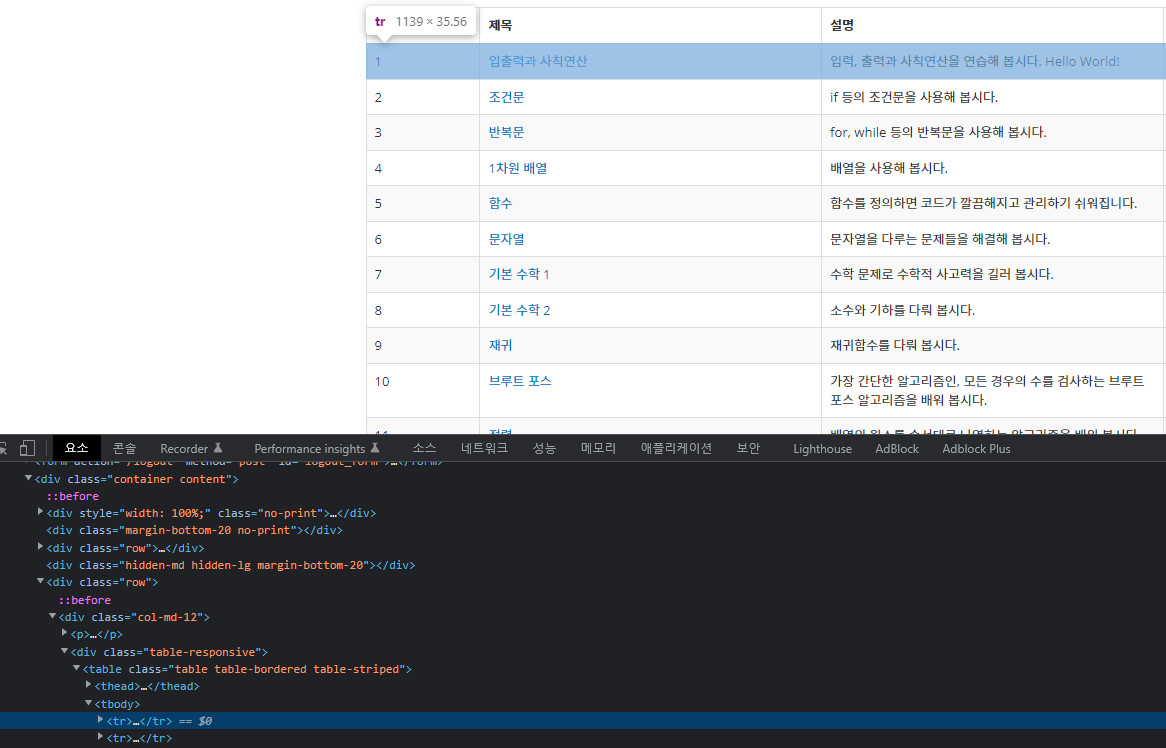
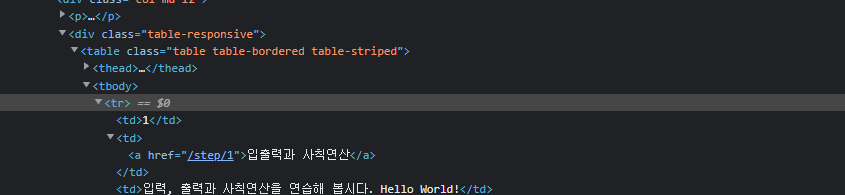
import requests
from bs4 import BeautifulSoup
url = 'https://www.acmicpc.net/step'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
main = soup.find("div", {"class": "table-responsive"})
body = main.find("tbody")
links = body.find_all("tr")
for link in links:
lnk = link.find("a").attrs['href']
steps = f"https://www.acmicpc.net{lnk}"
title = link.find("a").text
else:
print(response.status_code)위 코드를 실행하게 되면 (실행결과를 알기위해 steps 와 title 을 같이 출력하게 했다)

웹사이트에서 정상적으로 html 을 받아오는 사실도 알게되었고 출력을 통해 결과도 확인하였으니 원하는 내용을 받아오는 값을 출력하여보자
각 단계 별로 소제목 받아오기
이제는 각 단계별로의 소제목을 받아오면 되는데 각 단계별 소제목은 보다싶이 처음 링크한 main 화면에서는 찾아볼수 없고 위에서 받아온 링크로 들어가야지만 확인이 가능하다. 따라서 이 기능을 구현하려면 반복문을 하나 더 만들어서 받아온 링크로 request 하여 html 을 뽑아오는 작업을 해야한다.
그 전에 항상 우리가 블로그에 글을 작성할 때마다 모든 단계의 소제목과 내용이 필요한것도 아니고 실제로 가져오는데 시간도 오래걸리기 때문에 각 단계의 링크를 모두 받아온 다음에 필요한 단계가 몇단계인지 묻고 그 단계에 해당하는 데이터만 다시 BS를 통하여 파싱하도록 코드를 작성해본다.
for link in links:
lnk = link.find("a").attrs['href']
steps = f"https://www.acmicpc.net{lnk}"
step_list.append(steps)
# 필요한 링크를 모두 가져왔다.
need_step = input("필요한 단계를 입력하시오.")
steps = step_list[int(need_step)-1]
# request를 해오고 이를 BS로 html을 파싱해온다.
step_response = requests.get(steps)
if step_response.status_code == 200:
step_html = step_response.text
step_soup = BeautifulSoup(step_html, 'html.parser')메인 화면을 입력받았던과 마찬가지로 step_response에 링크를 받아오고 step_soup 에 BS를 통하여 html 을 파싱해왔다.
step 화면에서도 마찬가지로 f12로 html 요소를 받아와 원하는 곳에서 원하는 html 을 받아온다.
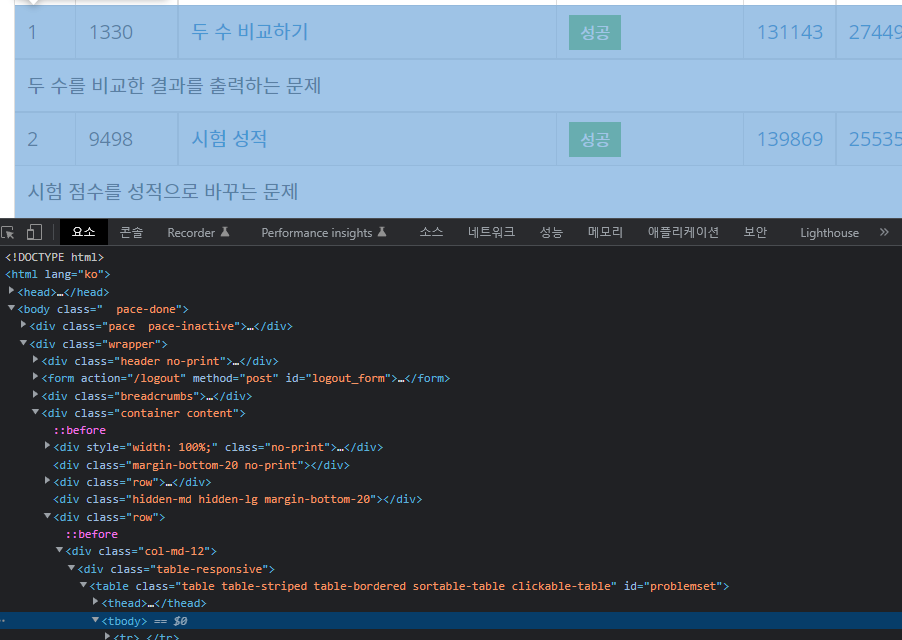
필요한 데이터를 가져오기 위해서는 항상 전략을 잘 세우는것이 중요하다.
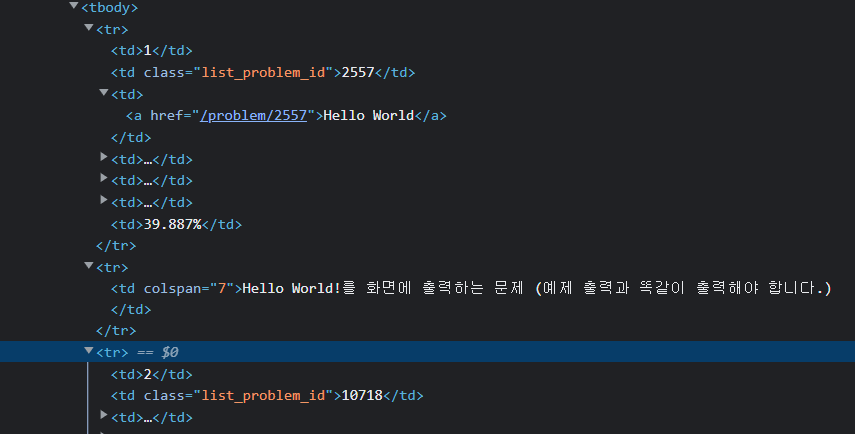
<tbody> 내의 각각의 <tr> 마다 문제가 하나씩 배치되어있었으면 좋겠지만 위 코드에서 보면 홀수번째에 문제에 대한 정보가 담겨있고 짝수번째에는 필요하지 않는 정보가 있는것을 확인 할 수 있다.
find_all 함수를 통하여 tr에 대한 정보를 가져올때 홀수번째만 가져오게 할수도 있고
조건문을 통하여 내부의 td 개수가 1개인 tr은 리스트에서 제외하라는 식으로도 작성할 수 있겠지만
지금 가져오는 정보 개수가 그렇게 많지 않음을 고려해서 모든 td를 가져오되, class 명이 list_problem_id 인 코드만 가져오게하여 num (문제번호)를 가져왔다.
if step_response.status_code == 200:
step_html = step_response.text
step_soup = BeautifulSoup(step_html, 'html.parser')
step_main = step_soup.find(
"div", {"class": "table-responsive"})
step_body = step_main.find("tbody")
nums = step_body.find_all("td", {"class", "list_problem_id"})
subtitles = step_body.find_all("tr")
for num in nums:
print(num.text)역시나 print 를 이용하여 제대로 출력이 되는지 확인하여본다.
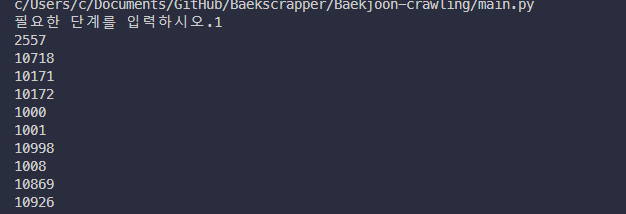
하지만 이런식으로 코드를 짜다보면 지금 번호는 구했지만 소제목도 구해야하는데 그럼 또 다른 for 구문을 통한 반복을 통하여 가져 와야한다. 홀 수 번째의 <tr> 덩어리에 같이 정보가 들어있는 구조를 활용해서 지금처럼 전체 html에서 번호 따로 소제목 따로 가져오는 방안보다는 tr 덩어리에서 가져오는 식으로 구현을 하는것이 좋다.
# request를 해오고 이를 BS로 html을 파싱해온다.
step_response = requests.get(steps)
if step_response.status_code == 200:
step_html = step_response.text
step_soup = BeautifulSoup(step_html, 'html.parser')
step_main = step_soup.find(
"div", {"class": "table-responsive"})
step_body = step_main.find("tbody")
pbs = step_body.find_all("tr")
for pb in pbs[0::2]:
nums = pb.find("td", {"class": "list_problem_id"}).text
subs = pb.find("a").text
print(nums, subs)
else:
print(f'errorcode: {step_response.status_code} at {steps}step')<tr> 구조 내에 문제와 관련된 유효한 정보가 들어있는 항목들이 홀수번째 항들이라서 [첫번째 값: 마지막값 : 간격]을 이용하여 pbs[0::2] 로 홀수번째 항을 선택하도록 하였다. 짝수번째 항을 선택하고 싶은 경우에는 [1::2]로 표현하여야한다.

이대로 복사해서 붙여넣으면서 써도 좋지만 완전 자동화를 원하기 때문에 여기에서 얻은 소제목이나 제목 등 필요한 요소들을 tstory 의 포스팅 방법 중에 html 형식으로 되어있는 서식화를 하려고 한다.
자동.. 기다려
파싱데이터 블로그 html 서식화
일단 기존의 html 서식 파일을 가져와서 코드에 단계에 관련된 정보만 넣어주면 해당 단계의 소제목이나 번호 설명 등이 전부 입력되어있는 html 파일이 출력되기를 원하기 때문에 우선 미리 작성해두었던 백준 2단계를 포스팅 한 글의 html 을 가져와 필수적인 부분만 남기고 간추리기를 해보았다.
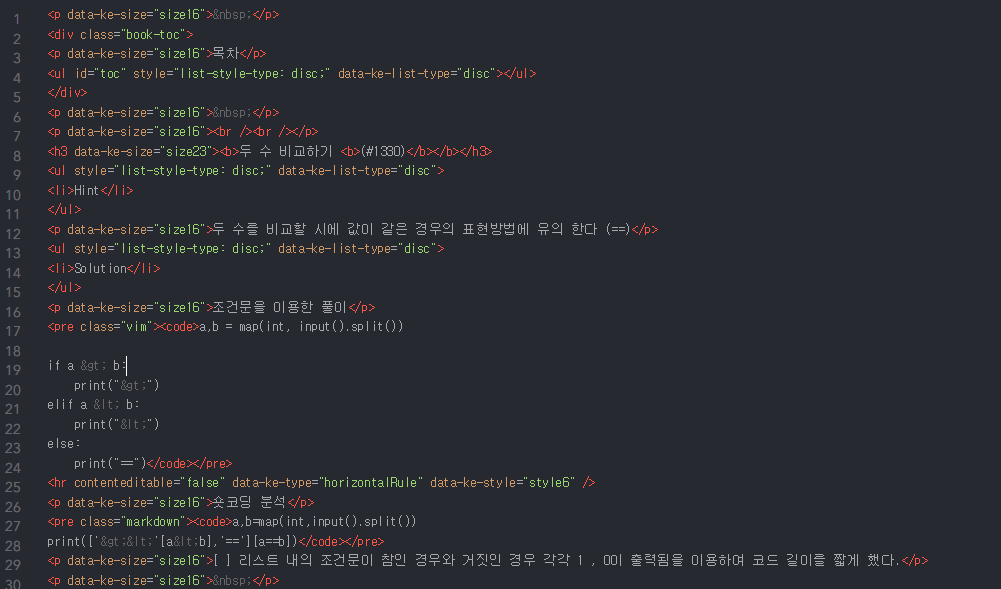
1~7줄까지의 코드는 목차 관련된 코드로 이는 항상 쓰이기 때문에 남겨놓는다.
8줄은 우리가 원하는 제목이나 번호 등이 들어가있기 때문에 이 줄부터 아래까지의 줄을 간추려서 반복문 안에 넣어두고 입력이 필요한부분을 num 과 sub에 저장되어있는 인자를 차례대로 배정하여 출력하게 코드를 짜야한다.
파이썬은 줄바꿈이 일어나면 ; 문장을 끝냈다고 생각하기 때문에 줄바꿈이 아무런 영향을 끼치지 않는 html 을 파이썬으로 가져오면 불편함이 야기될수도 있다. 이때는 파이썬 print 함수의 print(''' 내용 ''') 형식을 사용하면 줄바꿈을 해도 하나의 print 함수로 인식하게된다.
# 블로그 html 출력부
print('''
<p data-ke-size="size16"> </p>
<!-- 목차 부분 -->
<div class="book-toc">
<p data-ke-size="size16">목차</p>
<ul id="toc" style="list-style-type: disc;" data-ke-list-type="disc"></ul>
</div>
<p data-ke-size="size16"> </p>
<p data-ke-size="size16"><br /><br /></p>
<!-- 제목 -->
''')
for i in range(len(num)):
print(f'<h3 data-ke-size="size23"><b>{sub[i]}<b>(#{num[i]})</b></b></h3>')
print('''
<!-- Hint 란 -->
<ul style="list-style-type: disc;" data-ke-list-type="disc">
<li>Hint</li>
</ul>
<p data-ke-size="size16">두 수를 비교할 시에 값이 같은 경우의 표현방법에 유의 한다 (==)</p>
<!-- Solution 란 -->
<ul style="list-style-type: disc;" data-ke-list-type="disc">
<li>Solution</li>
</ul>
<p data-ke-size="size16">조건문을 이용한 풀이</p>
<!-- 코드 삽입란 -->
<pre class="vim">
<code>
code code
</code>
</pre>
<!-- 구분선 -->
<hr contenteditable="false" data-ke-type="horizontalRule" data-ke-style="style6" />
''')html 출력부
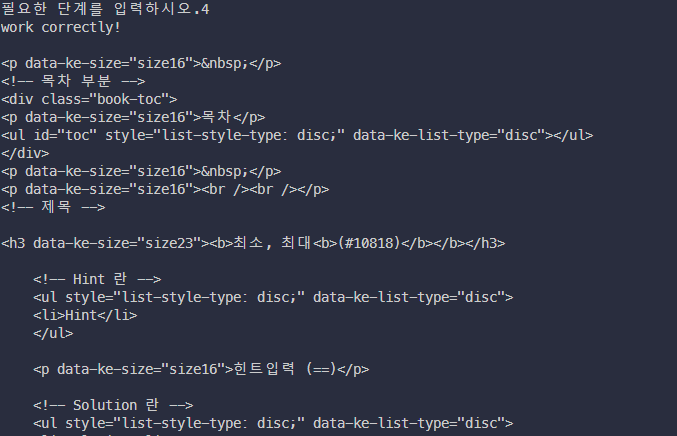
'미사용 > Blog Design' 카테고리의 다른 글
| [Python] 백준 크롤러 BOJcrawler 2.0.0 런칭 (0) | 2023.01.18 |
|---|