
목차
문제풀이를 하기 전에 이번 단계의 제목인 정렬과 이 단계가 시사하는 목적에 대해 요약하자면
여러가지 수열을 원하는 조건을 통하여 정렬시키는 알고리즘에는 여러가지 방법이 있는데 각 정렬의 방법마다 정렬에 걸리는 시간복잡도가 Best 최선의 경우 Average 평균의 경우 Worst 최악의 경우 등 데이터의 분포 등에 따라서 복잡도가 달라지는데 이번 목록에는 여러가지 정렬에 관련된 개념을 익히고 실습해보는것이 목적이다.
따라서 이번 단계에서는 숏코딩 보다는 정렬의 여러 방법을 사용하며 문제풀이를 하는 방향으로 풀이를 하겠다.
수많은 사람들이 알고리즘으 시간 복잡도에 대한 자세한 포스팅은 많이 존재하기 때문에 간단히 표를 통한 차이 정도만 넣어보았다.
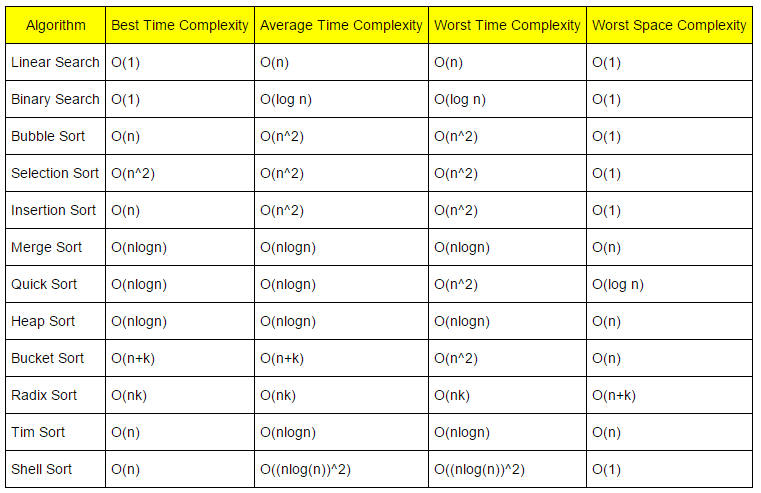
각 정렬 방식별 B Av W 그리고 space 복잡도도 넣어보았다. space 는 메모리 복잡도라고도 불린다.
수 정렬하기(#2750)
- Problem
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
- Hint
문제의 조건에 선택정렬과 버블 정렬을 이용하여 문제를 해결해보라고 하였다
- Solution
선택정렬을 이용한 풀이
n = int(input())
a=[]
for i in range(n):
a.append(int(input()))
td=0
for i in range(n-1):
for j in range(i+1):
if a[i+1-j]<a[i-j]:
td=a[i+1-j]
a[i+1-j]=a[i-j]
a[i-j]=td
print(*a, sep='\n')버블정렬을 이용한 풀이
n = int(input())
a=[]
for i in range(n):
a.append(int(input()))
td=0
for i in range(n-1):
for j in range(n-1-i):
if a[j+1]<a[j]:
td=a[j+1]
a[j+1]=a[j]
a[j]=td
print(*a, sep='\n')


목차의 표를 보게 되면 평균 시간복잡도는 같지만 최적 경우에는 시간 복잡도가 버블정렬이 더 우세함을 알 수 있다.
같은 문제에서 같은 input을 통하여 정답여부를 결정했을것이므로 평균 시간은 같지만 최적의 경우 우세로 시간이 적게 걸렸다고 유추해볼수 있다.
또한 메모리 사용도 td (temporary data)를 매번 저장한 1군데를 사용함을 알 수 있다.
수 정렬하기 2(#2751)
- Problem
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
- Hint
시간 복잡도가 O(nlogn)인 정렬 알고리즘으로 풀 수 있습니다. 병합 정렬, 힙 정렬을 이용하라고 한다.
- Solution
병렬 정렬을 이용한 풀이
import sys
sys.setrecursionlimit(10**6)
def merge_sort(list):
if len(list) <= 1:
return list
mid = len(list) // 2
leftList = list[:mid]
rightList = list[mid:]
leftList = merge_sort(leftList)
rightList = merge_sort(rightList)
return merge(leftList, rightList)
def merge(left, right):
result = []
while len(left) > 0 or len(right) > 0:
if len(left) > 0 and len(right) > 0:
if left[0] <= right[0]:
result.append(left[0])
left = left[1:]
else:
result.append(right[0])
right = right[1:]
elif len(left) > 0:
result.append(left[0])
left = left[1:]
elif len(right) > 0:
result.append(right[0])
right = right[1:]
res.append(result)
return result
res = []
addlist = []
n = int(input())
for i in range(n):
addlist.append(int(input()))
merge_sort(addlist)
print(*res[-1], sep='\n')
더이상 나뉠수 없을때까지 좌우 리스트로 나뉘게 하는 함수 merge_sort 와 그 나뉜 함수들의 대소를 비교하여 result 리스트에 추가하여 정렬을 하는 merge 함수로 이루어져있다.
힙 정렬을 이용한 풀이
# By not using seperate method;heap
def heap_sort(list):
while len(list) > 0:
result = []
while len(list) > 1:
if len(list) % 2 == 0:
l=list[len(list)-1]
m=list[int(len(list)/2-1)]
if l > m:
l,m=m,l
result.append(l)
list = list[:-1]
elif len(list) % 2 == 1:
l=list[len(list)-2]
m=list[int((len(list)-1)/2-1)]
r=list[len(list)-1]
if l > m:
l,m=m,l
elif r > m:
r,m=m,r
result.append(r)
result.append(l)
list = list[:-2]
res.append(*list)
list = result
addlist = []
n = int(input())
res = []
for i in range(n):
addlist.append(int(input()))
heap_sort(addlist)
print(res)힙정렬의 원리를 알아보기 위해 조금은 지저분하게 푼 풀이 결국에는 자식이 하나가 있는 경우와 아닌 경우로 나뉘어서 힙 정렬을 시행하였다.
수 정렬하기 3(#10989)
- Problem
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
- Hint
카운팅 정렬을 사용하여 풀으라고 하였다. 숫자의 개수가 작을때 사용하면 좋은방법이다. 일반적으로 우리에게는 숫자 10000이라는게 크게 느껴지지만 컴퓨터의 입장에선 그렇게 큰 수가 아니다.
- Solution
카운팅 정렬을 이용한 풀이
import sys
input = sys.stdin.readline
n = int(input())
result = [0]*10001
for i in range(n):
a = int(input())
result[a] += 1
for j in range(10001):
if result[j] != 0:
for k in range(result[j]):
print(j)10001개의 리스트를 만들어 놓고 숫자가 하나 입력될 때마다 그에 해당되는 칸에 1을 더해주어 카운팅 리스트를 완성하고 이후에 반복문을 또 주어 각 칸마다 입력되어있는 숫자만큼 그 칸의 번호가 출력되게 하였다.
커트라인(#25305)
- Problem
2022 연세대학교 미래캠퍼스 슬기로운 코딩생활에 $N$명의 학생들이 응시했다. 이들 중 점수가 가장 높은 $k$명은 상을 받을 것이다. 이 때, 상을 받는 커트라인이 몇 점인지 구하라. 커트라인이란 상을 받는 사람들 중 점수가 가장 가장 낮은 사람의 점수를 말한다.
- Hint
파이썬의 경우 간단히 sorted 내장 함수를 사용하여도 좋지만 요소의 개수가 작은 정렬 방식을 사용해도 좋다.
- Solution
sorted을 이용한 풀이
n,k=map(int,input().split())
score=[]
for i in map(int,input().split()):
score.append(i)
print(sorted(score)[n-k])score 함수에 저장을 해준뒤에 sorted 함수를 통하여 오름차순으로 정렬된 리스트의 n-k 번째의 score 요소를 출력해내는 방식으로 문제 풀이를 해주었다.
통계학(#2108)
- Problem
수를 처리하는 것은 통계학에서 상당히 중요한 일이다. 통계학에서 N개의 수를 대표하는 기본 통계값에는 다음과 같은 것들이 있다. 단, N은 홀수라고 가정하자. 산술평균 : N개의 수들의 합을 N으로 나눈 값 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값 최빈값 : N개의 수들 중 가장 많이 나타나는 값 범위 : N개의 수들 중 최댓값과 최솟값의 차이 N개의 수가 주어졌을 때, 네 가지 기본 통계값을 구하는 프로그램을 작성하시오.
- Hint
시간초과가 뜨면 input대신에 sys.stdin.readline을 사용하여 보자
2022.07.24 - [Python] - sys.stdin.readline()
리스트 요소의 위치를 구할때 round는 되도록 사용하지 말자.
n=5일 때 round(n/2)를 하면 3이 아니라 2가 나온다. 그 이유는 2.4999999를 반올림 하기 때문
- Solution
index()을 이용한 풀이
import sys
n = int(sys.stdin.readline().strip())
num=[]
for i in range(n):
rd = int(sys.stdin.readline().strip())
num.append(rd)
count=[0]*8001
for i in num:
i+=4000
count[i]+=1
fi=count.index(max(count))
if fi<8000 and max(count)==max(count[fi+1:]):
c=fi-4000+count[fi+1:].index(max(count))+1
else:
c=fi-4000
a=round(sum(num)/n)
b=sorted(num)[int((n-1)/2)]
d=max(num)-min(num)
print(a,b,c,d,sep='\n')값의 범위가 +-4000 밖에 되지 않아 카운팅 정렬을 이용하였다. 하지만 카운팅 정렬시에 리스트의 index 가 음수가 될 수 없기에 최소 음수 범위인 -4000을 커버하기 위해서 전체 index에 4000을 더하여 주고 나중에 최종 계산시에 4000을 다시 빼주었다.
중앙값을 구하기 위해서는 위 힌트에도 적었던 오류를 피하기 위해 항상 홀수라는 점을 이용하여 전체에서 1을 뺀 나머지를 2로 나누어 이를 index 로 받는 리스트의 값을 출력했고
최빈값의 경우에는 일단 문제의 조건에 있던 최빈값이 여러개 존재 할 시에는 2번째의 최소값을 사용하라는 조건을 만족시키기 위하여 카운팅 리스트의 [FixedIndex+1:] 범위 내에도 max(count)의 값이 있는지에 대해 확인하여 있을시에(2개이상 존재)는 2번째 값을 나오게 하였다. 또한 최대 인덱스인 4000이 들어왔을 경우엔 카운팅 리스트 특성상 4001번째(fi 기준 8001) 리스트가 존재하지 않기 때문에 and 조건을 사용하여 8000 미만 일 경우라는 조건을 추가해주었다.
PS 다 풀어놓고 input 으로 인한 시간초과가 계속 일어나서 당황했다.. 앞으로는 readline을 사용하는 것을 습관화 해야겠다.
소트인사이드(#1427)
- Problem
배열을 정렬하는 것은 쉽다. 수가 주어지면, 그 수의 각 자리수를 내림차순으로 정렬해보자.
- Hint
문자열로 받고 다시 리스트에 정수형으로 저장해주고 내림차순 정렬을 해주면 된다.
- Solution
[::-1]을 이용한 풀이
n = str(input())
sl=[]
for i in n:
sl.append(int(i))
print(*sorted(sl)[::-1],sep='')sorted 함수는 오름차순 정렬이기 때문에 [::-1]을 이용하여 뒤에서 부터 출력을 하게 해주었다.
다른 방법으로 sort 함수와 reverse 옵션을 이용해서 리스트.sort(reverse = True) 형식으로 나타내주어도 내림차순으로 출력해낼수가 있다.
좌표 정렬하기(#11650)
- Problem
2차원 평면 위의 점 N개가 주어진다. 좌표를 x좌표가 증가하는 순으로, x좌표가 같으면 y좌표가 증가하는 순서로 정렬한 다음 출력하는 프로그램을 작성하시오.
- Hint
역시나 이것도 파이썬의 내장함수 sort로 쉽게 풀리게 된다.
- Solution
sorted을 이용한 풀이
n = int(input())
sl=[]
for i in range(n):
a,b=map(int,input().split())
sl.append([a,b])
for j in sorted(sl):
print(*j)sorted list 안에 2차원 배열 즉 또 다른 리스트를 넣어서 sorted 나 sort 를 적용시키게되면 각각의 자리수 모두 오름차순을 통하여 정렬해준다.
여담으로 퀵정렬을 이용하여 정렬을 할 경우엔 시간 제한이 줄어들기 전에는 통과를 하였는데 재채점 이후 시간초과가 떴다는 글이 있었다. 코드를 읽어보았을때 코드에는 문제가 없던 것으로 보아서 파이썬을 통하여 정렬을 할 경우 내장함수 sort를 쓰라는 것 같았다.
좌표 정렬하기 2(#11651)
- Problem
2차원 평면 위의 점 N개가 주어진다. 좌표를 y좌표가 증가하는 순으로, y좌표가 같으면 x좌표가 증가하는 순서로 정렬한 다음 출력하는 프로그램을 작성하시오.
- Hint
sort의 특징을 잘 이용하여보자
- Solution
sorted, [::-1]을 이용한 풀이
n = int(input())
sl=[]
for i in range(n):
a,b=map(int,input().split())
sl.append([b,a])
for j in sorted(sl):
print(*j[::-1])앞의 문제와 원하는 형식은 같지만 조건이 다른 경우이다. sort 내장 함수가 각 요소들의 첫번째 값부터 오름차순을 시키는 것을 이용하여 y를 앞에 두고 정렬을 시킨뒤에 출력시에 순서만 바꿔서 내주면 쉽게 해결된다.
단어 정렬(#1181)
- Problem
알파벳 소문자로 이루어진 N개의 단어가 들어오면 아래와 같은 조건에 따라 정렬하는 프로그램을 작성하시오. 길이가 짧은 것부터 길이가 같으면 사전 순으로
- Hint
힌트입력 (==)
- Solution
리스트를 이용한 풀이
n = int(input())
sl=[]
for i in range(n):
w=str(input())
sl.append([len(w),w])
td=0
for j in sorted(sl):
if td!=j[1]:
print(j[1])
td=j[1]위의 문제와 비슷하게 풀었는데 다만 앞 부분에 len(w) 즉 받아오는 단어의 수를 저장하여 나중에 이를 기준으로 sort 가 진행되고 뒤에 있는 str 형은 sort를 사용하여 정렬되게 하였다. 그리고 중복되는 값은 또 출력이 되지 않게 하기 위해서 td 값과 비교하여 전의 출력 값과 다른경우에만 출력이 되게 하였다.
나이순 정렬(#10814)
- Problem
온라인 저지에 가입한 사람들의 나이와 이름이 가입한 순서대로 주어진다. 이때, 회원들을 나이가 증가하는 순으로, 나이가 같으면 먼저 가입한 사람이 앞에 오는 순서로 정렬하는 프로그램을 작성하시오.
- Hint
입력은 먼저 가입한 순서대로 주어지고 출력도 마찬가지로 가입순으로 출력을 해야한다. 이런 것을 안정 정렬이라고 한다.
결국에는 입력 순서도 순서(sort 대상) 이 아닌가?
- Solution
반복문의 인자를 이용한 풀이
n = int(input())
sl=[]
for i in range(n):
a,b=map(str,input().split())
sl.append([int(a),i,b])
for j in sorted(sl):
print(j[0],j[2])첫번째 반복문의 i는 n-1 이 되기 전까지 쭉 증가를 하게 되는데 전체 sort 시에 이를 인자로 두어 정렬하게 되면 뒤에 있는 사전형이 어떻던지 상관이 없게 된다. 무척 간단하게 풀리는 문제
좌표 압축(#18870)
- Problem
수직선 위에 N개의 좌표 X1, X2, ..., XN이 있다. 이 좌표에 좌표 압축을 적용하려고 한다. Xi를 좌표 압축한 결과 X'i의 값은 Xi > Xj를 만족하는 서로 다른 좌표의 개수와 같아야 한다. X1, X2, ..., XN에 좌표 압축을 적용한 결과 X'1, X'2, ..., X'N를 출력해보자.
- Hint
.index는 시간 복잡도가 O(N)이므로 시간복잡도가 이보다 작은 것을 이용하여 사용해보자. 이진탐색의 경우 : O(logN)
- Solution
이진탐색을 이용한 풀이
import sys
input=sys.stdin.readline
n = int(input())
sl=[]
for i in map(int,input().split()):
sl.append(i)
nsl=sorted(set(sl))
def binary_search(list,value):
first,last = 0,len(list)
while first <= last:
mid = (first+last) //2
if list[mid] == value:
return mid
if list[mid] > value:
last = mid - 1
else:
first = mid +1
for j in sl:
print(binary_search(nsl,j),end=' ')
마지막의 경우 처음에는 nsl.index(j)를 출력하는 구문을 사용했다. 하지만 시간초과가 뜨게 되었고 내장 함수인 index 의 시간 복잡도를 검색해본 결과 O(1) 로서 중복되는 값이 하나도 없는 경우를 수행할 땐 O(1)*N 즉 O(N)이 되는 것이다. 따라서 시간 복잡도가 O(logN)인 이진 탐색법을 사용하여 문제를 풀었다.
'Baekjoon > Stepbystep' 카테고리의 다른 글
| [백준/python] 기하 1 전체 풀이(13단계) (1) | 2022.08.31 |
|---|---|
| [백준/python] 집합과 맵 전체 풀이(12단계) (0) | 2022.08.29 |
| [백준/python] 브루트 포스 전체 풀이(10단계) (0) | 2022.08.08 |
| [백준/python] 재귀 전체 풀이(9단계) (0) | 2022.08.04 |
| [백준/python] 기본 수학 2 전체 풀이(8단계) (0) | 2022.08.02 |